
Lately one of my customers had some issues with his VMware vSphere environment where the semi-outage of one ESXi took down quit a huge amount of his VMs. After fixing the issue in his productive infrastructure and bringing back his IT everything seamed working again. Some days later we noticed Errors in some of his Veeam Backup Jobs. Strangely not all VMs where affected and those affected had no direct correlation (e.g. same ESXi host, same datastore, some network, etc.).
The error message shown inside the Veeam Backup & Replication console was an error I have not seen before:
Error: DiskLib error: [4].A file error was encountered -- Failed to read the file
Error Failed to retrieve next FILE_PUT message. File path: [[<DATASTORE>] <VMFOLDER>/<VM>.vmx]. File pointer: [0]. File size: [3802].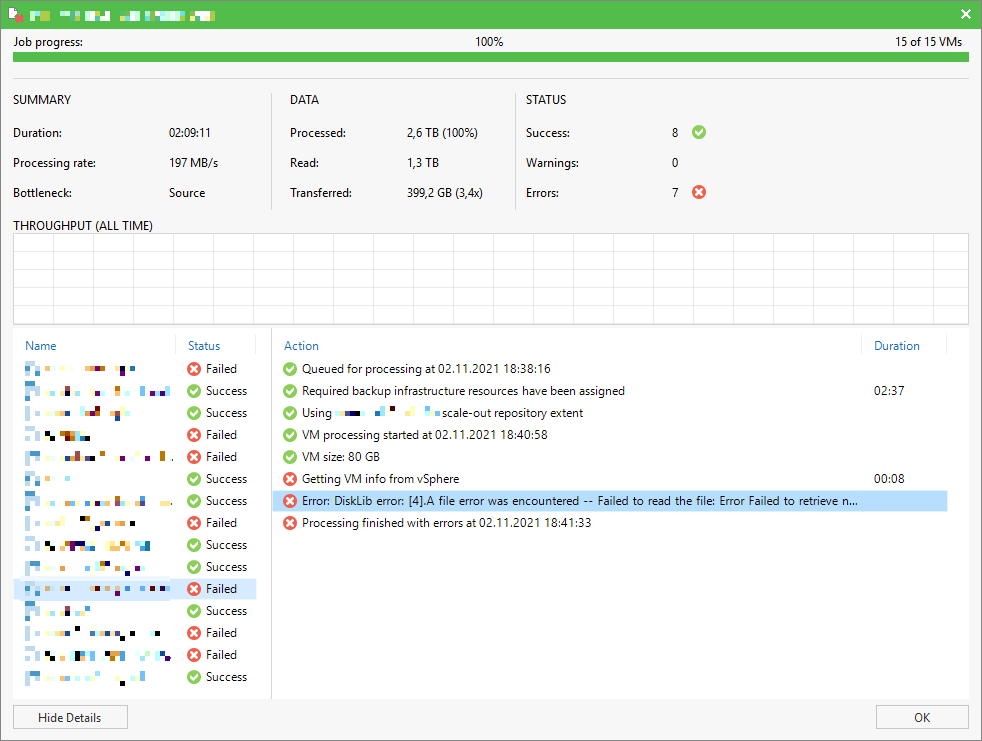
Error Failed to retrieve next FILE_PUT message. File path: [[<DATASTORE>] <VMFOLDER>/<VM>.vmx]. File pointer: [0]. File size: [3802].
After a little digging inside the Backup Job itself without success we switched over to the VMware vSphere side and startet to look into the affected VMs. All of them where running without any issues or other conspicuous behaviour. Regardless, we wanted to take a look at the corresponding log files.
This is where the strange behaviour startet. We were unable to download the log files from underlying datastore. We tired to collect the logs through vCenter and directly on the ESXi host. Same outcome using both options. After a quick brainstorming we came back with the idea to move the VM to a different datastore and try our luck again. At about 30% of the Storage vMotion the operation crashed with the error below.
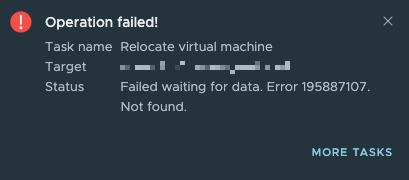
Checking the Events tab inside the vCenter GUI revealed some details which where more ore less useful because we were not able to access the referenced logs.
Failed waiting for data. Error 195887107. Not found. Failed to create one or more destination files. A fatal internal error occurred. See the virtual machine's log for more details.Last idea we came up with was to remove the affected VMs from the vCenter inventory and try to reregister them as a new VM. Because some of the affected VMs are part of a mission critical business application we tried our luck first with one of the less critical systems. We followed the the outline procedure below.
- Shutdown the VM
- Check VM configuration for the location of VMDK and VMX files on the datastores
- Remove the VM from vCenter inventory, keep files on datastores
- Navigate to the datastore location identified in step 2 and re-register the VM using the VMX file and the „REGISTER VM“ operation
- Power On the newly registered VM
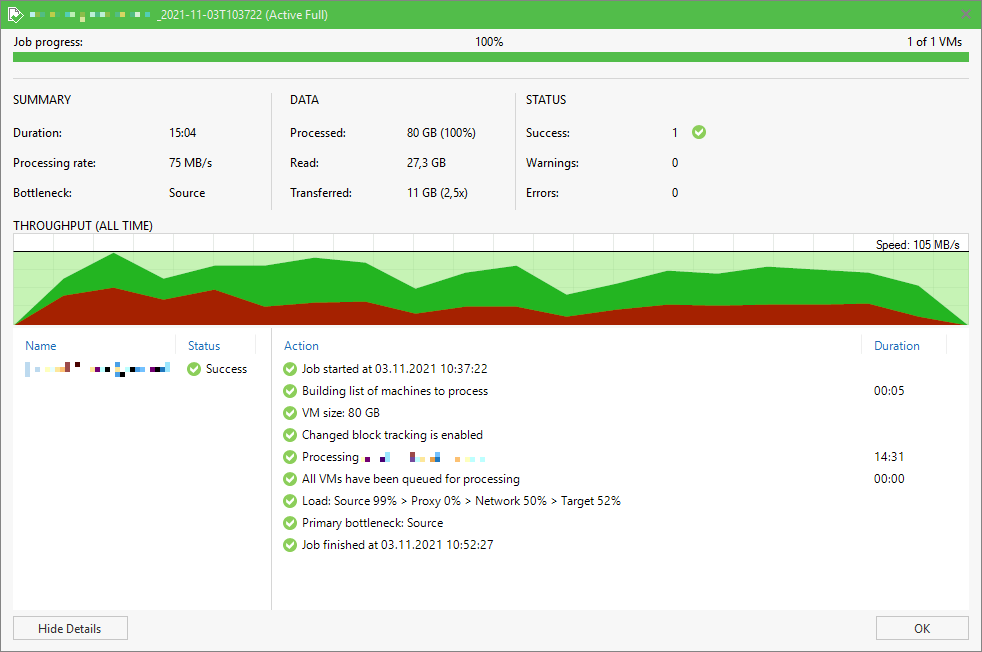
After the re-registration of the VM we tried the Storage vMotion operation again. This time the operation completed successful. This initial success made us hopeful and we switched back to the Veeam Backup & Replication console.
First we wanted to try a Veeam Quick Backup of the VM but quickly realised that the changed VM ID caused by the re-registration required us to perform a new full backup of the VM. For our test VM we decided to run a standalone full backup using VeeamZIP.
Shortly after starting the VeeamZIP job we had reason to be happy, after re-registering the VM not only the Storage vMotion operation worked but also Veeam Backup & Replication was able to backup the VM successfully again.
Wrap-Up
Personally, I’ve never seen this error before, so I’m even happier that not all VMs were affected by this issue after the mysterious crash of the VMware vSphere environment. Not only was a downtime of the applications necessary to re-register the VMs in vCenter, no a full backup of each affected VM had to be created due to the newly created IDs. If the entire cluster had been affected, I could have expected a few night shifts.