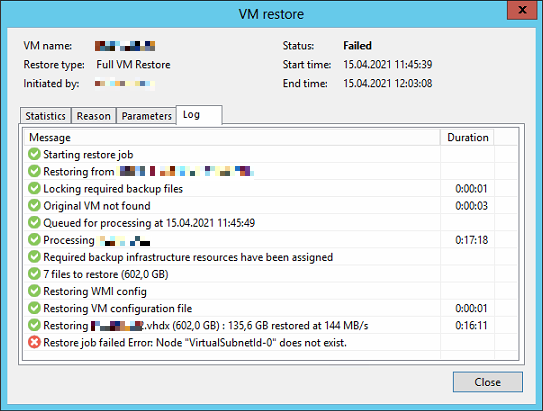
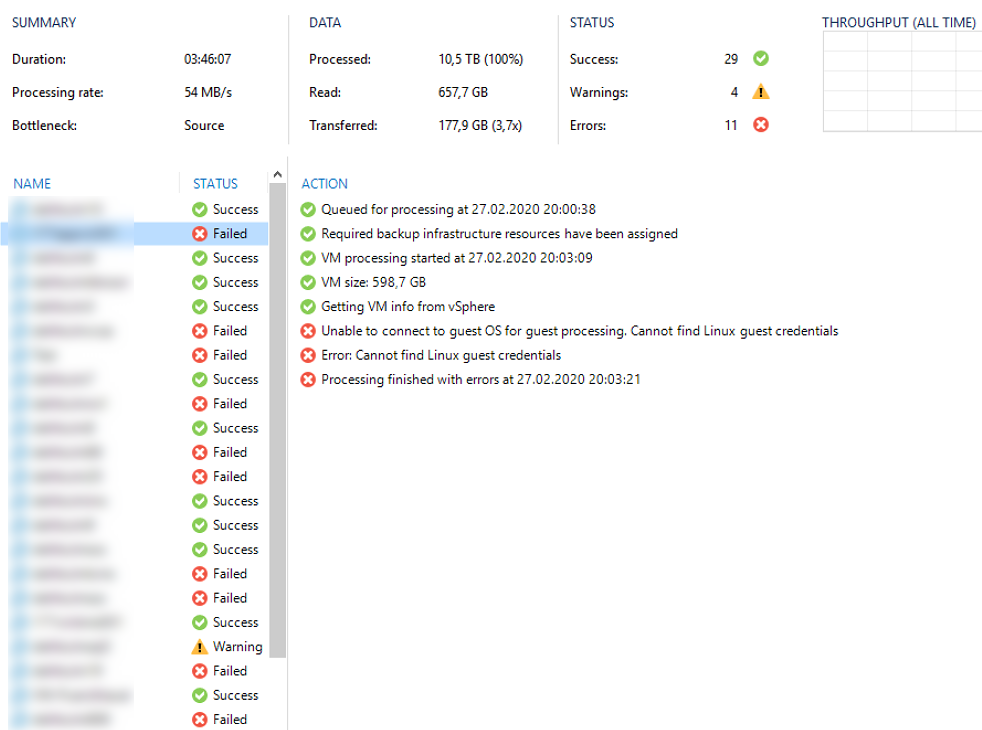
Lately one of my customers had some issues with his VMware vSphere environment where the semi-outage of one ESXi took down quit a huge amount of his VMs. After fixing the issue in his productive infrastructure and bringing back his IT everything seamed working again. Some days later we noticed Errors in some of his Veeam Backup Jobs. Strangely not all VMs where affected and those affected had no direct correlation (e.g. same ESXi host, same datastore, some network, etc.).
The error message shown inside the Veeam Backup & Replication console was an error I have not seen before:
Error: DiskLib error: [4].A file error was encountered -- Failed to read the file
Error Failed to retrieve next FILE_PUT message. File path: [[<DATASTORE>] <VMFOLDER>/<VM>.vmx]. File pointer: [0]. File size: [3802].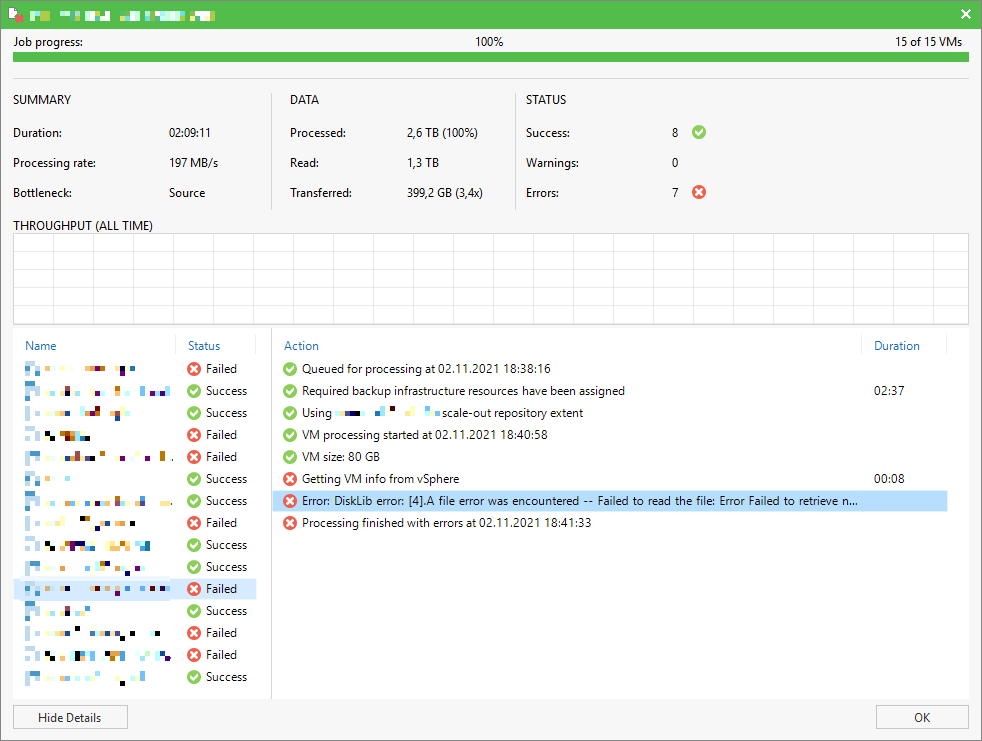
Error Failed to retrieve next FILE_PUT message. File path: [[<DATASTORE>] <VMFOLDER>/<VM>.vmx]. File pointer: [0]. File size: [3802].